

| | Parallel Linear System Solution Using ScaLapack |
Our aim here is to understand how we can use existing parallel libraries for performing linear algebra tasks in our own code. In particular, we will work with ScaLAPACK ("Scalable Linear Algebra Package"), which is an MPI-parallel version of LAPACK. For those who are using the serial LAPACK routines, it is a welcome feature of ScaLAPACK that all functions have the same name as in LAPACK except for a prefaced "P" (note: not all LAPACK functions are available in ScaLAPACK, but the most important ones are).
The detailed user guide for ScaLAPACK is available at NETLIB. The official site for BLACS is here.
Advantages of using ScaLAPACK:
Possible inconveniences:
The library ScaLAPACK builds upon a set of communication routines which are themselves a library, called "BLACS" (Basic Linear Algebra Communication Subprograms). Furthermore, with ScaLAPACK comes an additional library "PBLAS", which is the parallel analogue of "BLAS" (Basic Linear Algebra Subprograms). The schematic is shown below:
parallel code serial code
------------- -----------
ScaLAPACK & PBLAS LAPACK & BLAS
| |
BLACS |
| |
MPI |
| |
FORTRAN FORTRAN
With PBLAS simple matrix/vector operations can be performed in parallel. With ScaLAPACK, more complex operations can be carried out:
This means in practice that all of the components need to be installed in order to be able to use ScaLAPACK. On a Debian system, the necessary libraries (supposing you use the GNU compilers and MPICH) are installed in the system-wide libary directory (/usr/lib/):
libblacs-mpich.a
libblacsF77init-mpich.a
libblacsCinit-mpich.a
libscalapack-mpich.a
Alternatively, you can simply download and install from sources available at NETLIB (ScaLAPACK,
BLACS).
Processor Grid
In BLACS, and therefore in ScaLAPACK, the processors need to be arranged in a 2D processor grid, i.e. a processor is identified by two indices: one for its row (say my_row) and one for its column in the grid (say my_col). BLACS provides functions for setting-up this grid and for converting the unique MPI ranks (my_rank in our previous examples) to processor grid indices (my_row, my_col) and vice-versa. Therefore, the following holds for a communicator with nprocs processors distributed in a nrows x ncols processor grid:
0<=my_rank<=nprocs-1
0<=my_row<=nrows-1
0<=my_col<=ncols-1
nprocs=nrows*ncols
Commands used in the initial phase of the program:
call BLACS_PINFO(my_rank,nprocs)
retrieves the rank and the total number of available processors.
call BLACS_GET(-1,0,icontxt)
retrieves a so-called "context" icontxt (integer handle) for use in subsequent ScaLAPACK calls.
call BLACS_GRIDINIT(icontxt,order,nrows,ncols)
initializes a 2D processor grid consisting of nrows x ncols processors. the argument order is either "R" for "row-major" or "C" for "column-major, indicating which of the processor indices vary fastest.
The utility routine
call SL_INIT(icontext,nrows,ncols)
simplifies life slightly by directly returning a context for a given number of desired rows and columns (i.e. it can be used instead of BLACS_PINFO, BLACS_GET and BLACS_GRIDINIT). Afterwards,
call BLACS_GRIDINFO(icontxt,nrows,ncols,my_row,my_col)
returns the current processor's grid indices my_row ,my_col.
Data Decomposition: Block-Cyclic
In BLACS data is distributed in so-called "block-cyclic" manner. This means that for a pre-defined block size (say mb), m data are distributed in consecutive blocks of length mb to each processor (if m does not divide evenly by mb there is one final smaller block). This concept is completely different from the strategy we adopted in the Jacobi iteration case. The justification comes from the type of work which is typically done in linear algebra and aims at keeping all processors busy even if the overall size changes (e.g. Gauss elimination). The size mb of the blocks is a quantity which needs to be provided by the user and in practice one needs to find an optimum.
The online tutorial provides some more information and examples of block-cyclic data distribution.
Array Descriptor
BLACS/ScaLAPACK use a so-called "array descriptor" (an integer array) for describing how data corresponding to a global matrix is distributed over the processor grid,
integer desc(9)
These descriptors need to be supplied to all ScaLAPACK routines along the actual data. This means that you need one such descriptor for each matrix/vector with a distinct size. E.g. for a matrix-vector product you need two descriptors, one for the matrix, one for the vector; the resulting vector can use the same descriptor as the initial one since their size and distribution will be identical. There is an auxiliary routine for initializing this descriptor:
call DESCINIT(desc,m,n,mb,nb,rsrc,csrc,icontxt,lld,info)
where desc is the resulting descriptor; m, n are the two dimensions of the global array; mb, nb are the block sizes for the block-cyclic distribution of the rows and columns, respectively; rsrc, csrc are typically 0; icontext is the blacs context previously determined by a call to BLACS_GET; lld is the leading dimension of the local array; info is a return value (0 if no error occurred).
Linear System Solution
The following routines perform the solution of a linear system in parallel. The matrix is assigned analytically, and therefore no input operation is necessary, which in turn simplifies the code. Please go ahead and inspect the code in order to learn about the steps to successful parallel execution in detail. The code also contains a call to LAPACK (in the single processor case only) which helps to find out if the result is correct and lets us determine the speed-up with respect to the single-processor case.
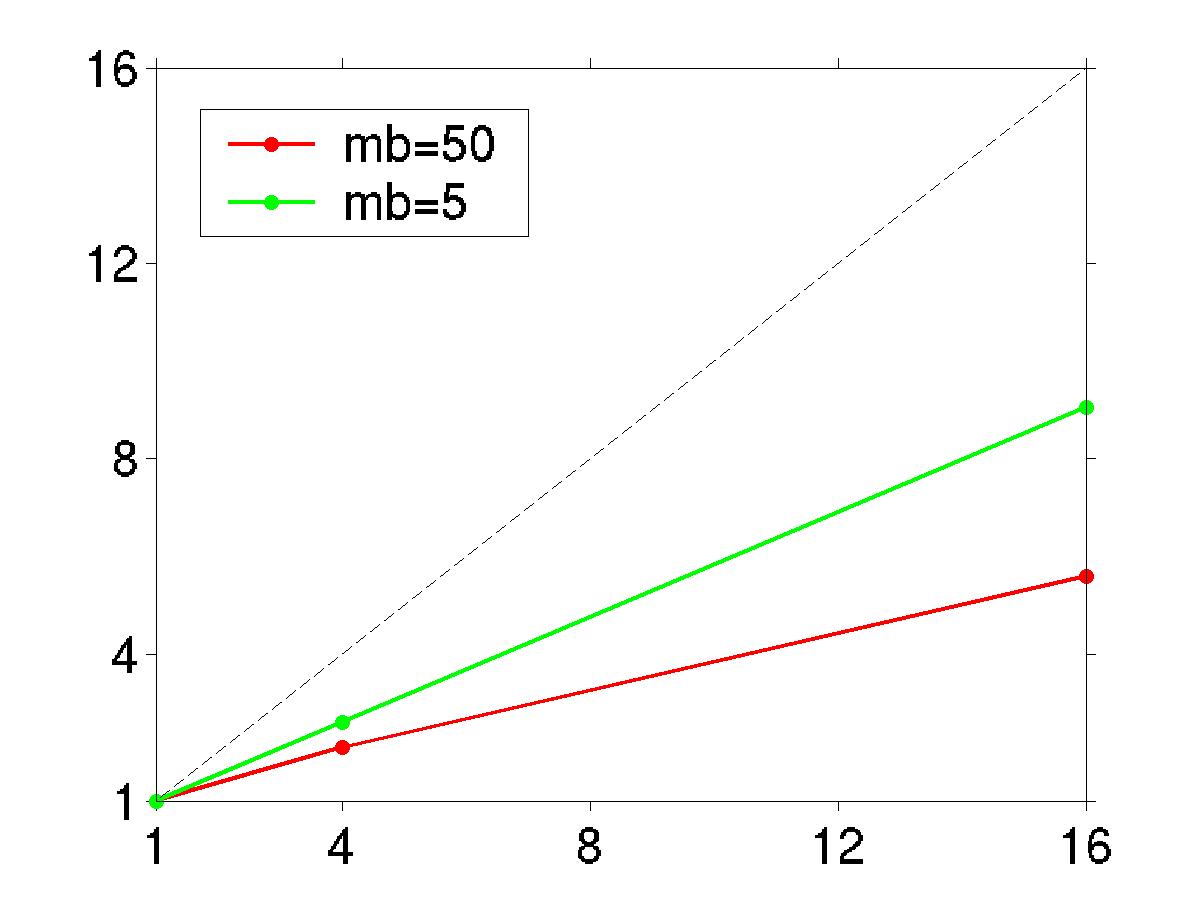
Timing of the above code on jen50.ciemat.es is plotted in this graph (eps, jpg, tiff) for a matrix size of 10000. It can be seen that the block-size makes a huge difference. For this particular example, we can obtain a 9-fold speed-up using 16 processors when choosing a block-size of mb=nb=50.
If you wish to explore the possibilities of ScaLAPACK further, you can take the above code as a stencil for your own program and implement further linear algebra operations.
markus.uhlmann AT ifh.uka.de
| | Parallel Linear System Solution Using ScaLapack |
{kind=link}